A Survey on Hallucination in Large Language Models: Principles, Taxonomy, Challenges, and Open Questions
A Survey on Hallucination in Large Language Models: Principles, Taxonomy, Challenges, and Open Questions
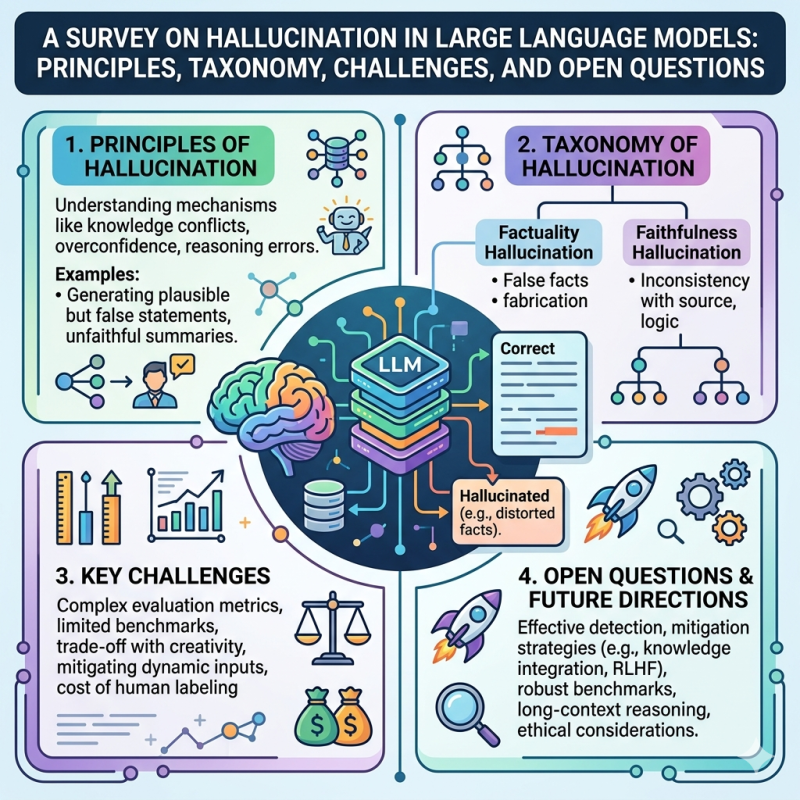
Research questions. This survey asks what counts as hallucination in LLMs, why hallucinations occur, and how they can be detected, evaluated, and mitigated. It also asks how hallucination changes in newer settings such as retrieval-augmented generation and vision-language models.
Methodology. This is a literature review, not a new experiment. The authors synthesize prior work into a taxonomy of hallucination types, causes, detection methods, benchmarks, mitigation strategies, and open research problems.
Findings. The paper argues that LLM hallucination is especially challenging because general-purpose, open-ended systems fail differently from older task-specific NLP models. It finds that hallucinations arise from multiple sources, including data, training, decoding, and limitations in models’ knowledge boundaries, and that even retrieval-augmented systems still face hallucination risks.
Why it matters. The survey is useful because it organizes a scattered research area into a practical framework for studying reliability. For sycophancy and alignment work, it helps distinguish factual unreliability from other failure modes while showing why confident, plausible-sounding errors remain a core risk in real-world AI use.