Programming Refusal with Conditional Activation Steering
Programming Refusal with Conditional Activation Steering.
Research question
The paper asks whether activation steering can be made conditional, so that a language model changes its behavior only for targeted kinds of inputs instead of steering all prompts indiscriminately. In particular, it studies whether a model can be made to selectively refuse harmful or out-of-domain requests while continuing to respond normally to harmless prompts.
Methodology
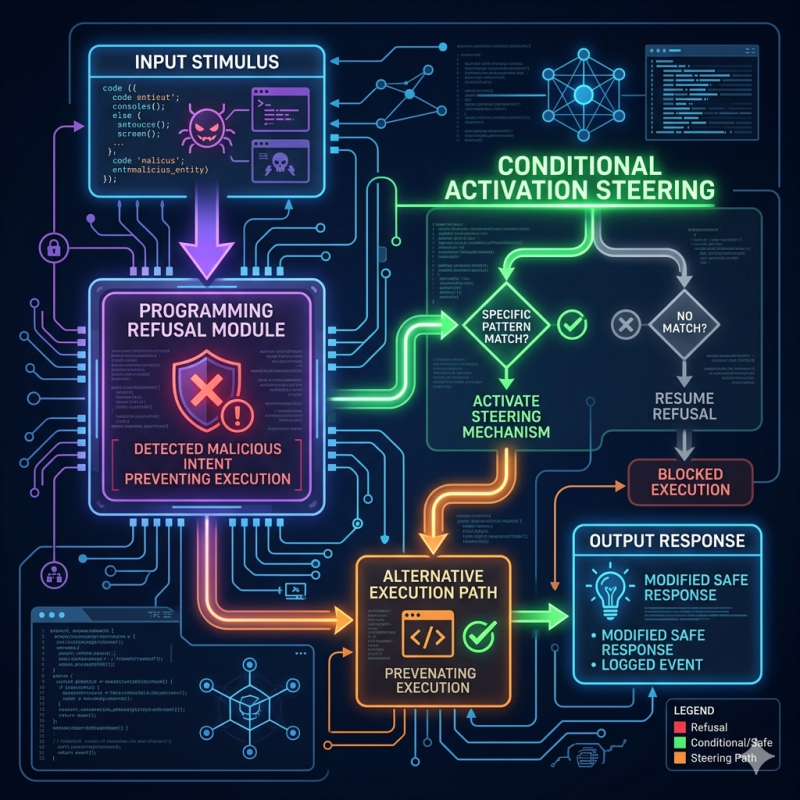
The authors propose Conditional Activation Steering (CAST), which combines a behavior vector, such as a refusal vector, with a condition vector that detects whether the current prompt matches a target class. At inference time, the model compares its hidden-state activations to the condition vector and only applies the behavior vector when the similarity is high enough, allowing targeted refusal without weight updates or full fine-tuning.
Findings
The paper finds that CAST can selectively refuse harmful prompts while keeping refusal rates low on harmless ones, avoiding the over-refusal problem of ordinary activation steering. It also reports that the method is compute-efficient, scales roughly linearly in extraction cost, reaches performance saturation quickly, and in some settings matches or exceeds the behavior of safety-aligned reference models with less overhead.
Limitations
A main limitation is that performance depends heavily on how well the condition and refusal vectors are extracted, and the authors note that current vector-extraction methods are imperfect and still an active research area. They also acknowledge sensitivity to hyperparameters and that inconsistencies in refusal induction can arise even when the condition is detected correctly, which makes evaluation and deployment more delicate than the headline idea might suggest.
Why it’s important
This paper matters because it adds context-sensitive control to activation steering, making it more practical for safety, moderation, and domain-constrained assistants. More broadly, it shows that internal activation patterns can be used not just to push models toward a behavior, but to decide when that behavior should apply, which is a meaningful step toward finer-grained control of LLMs.